Serialization Format
This page describes the XRP Ledger's canonical binary format for transactions and other data. This binary format is necessary to create and verify digital signatures of those transactions' contents, and is also used in other places including in the peer-to-peer communications between servers. The rippled APIs typically use JSON to communicate with client applications. However, JSON is unsuitable as a format for serializing transactions for being digitally signed, because JSON can represent the same data in many different but equivalent ways.
The process of serializing a transaction from JSON or any other representation into their canonical binary format can be summarized with these steps:
-
Make sure all required fields are provided, including any required but "auto-fillable" fields.
The Transaction Formats Reference defines the required and optional fields for XRP Ledger transactions.
Note: The
SigningPubKeymust also be provided at this step. When signing, you can derive this key from the secret key that is provided for signing. -
Convert each field's data into its "internal" binary format.
-
Sort the fields in canonical order.
-
Prefix each field with a Field ID.
-
Concatenate the fields (including prefixes) in their sorted order.
The result is a single binary blob that can be signed using well-known signature algorithms such as ECDSA (with the secp256k1 elliptic curve) and Ed25519. For purposes of the XRP Ledger, you must also hash the data with the appropriate prefix (0x53545800 if single-signing, or 0x534D5400 if multi-signing). After signing, you must re-serialize the transaction with the TxnSignature field included.
Note: The XRP Ledger uses the same serialization format to represent other types of data, such as ledger objects and processed transactions. However, only certain fields are appropriate for including in a transaction that gets signed. (For example, the TxnSignature field, containing the signature itself, should not be present in the binary blob that you sign.) Thus, some fields are designated as "Signing" fields, which are included in objects when those objects are signed, and "non-signing" fields, which are not.
Examples
Both signed and unsigned transactions can be represented in both JSON and binary formats. The following samples show the same signed transaction in its JSON and binary formats:
JSON:
{
"Account": "rMBzp8CgpE441cp5PVyA9rpVV7oT8hP3ys",
"Expiration": 595640108,
"Fee": "10",
"Flags": 524288,
"OfferSequence": 1752791,
"Sequence": 1752792,
"SigningPubKey": "03EE83BB432547885C219634A1BC407A9DB0474145D69737D09CCDC63E1DEE7FE3",
"TakerGets": "15000000000",
"TakerPays": {
"currency": "USD",
"issuer": "rvYAfWj5gh67oV6fW32ZzP3Aw4Eubs59B",
"value": "7072.8"
},
"TransactionType": "OfferCreate",
"TxnSignature": "30440220143759437C04F7B61F012563AFE90D8DAFC46E86035E1D965A9CED282C97D4CE02204CFD241E86F17E011298FC1A39B63386C74306A5DE047E213B0F29EFA4571C2C",
"hash": "73734B611DDA23D3F5F62E20A173B78AB8406AC5015094DA53F53D39B9EDB06C"
}
Binary (represented as hexadecimal):
120007220008000024001ABED82A2380BF2C2019001ABED764D55920AC9391400000000000000000000000000055534400000000000A20B3C85F482532A9578DBB3950B85CA06594D165400000037E11D60068400000000000000A732103EE83BB432547885C219634A1BC407A9DB0474145D69737D09CCDC63E1DEE7FE3744630440220143759437C04F7B61F012563AFE90D8DAFC46E86035E1D965A9CED282C97D4CE02204CFD241E86F17E011298FC1A39B63386C74306A5DE047E213B0F29EFA4571C2C8114DD76483FACDEE26E60D8A586BB58D09F27045C46
Sample Code
The serialization processes described here are implemented in multiple places and programming languages:
- In C++ in the
rippledcode base . - In JavaScript in this repository's code samples section .
- In Python 3 in this repository's code samples section .
Additionally, many client libraries provide serialization support under permissive open-source licenses, so you can import, use, or adapt the code for your needs.
Internal Format
Each field has an "internal" binary format used in the rippled source code to represent that field when signing (and in most other cases). The internal formats for all fields are defined in the source code of SField.cpp . (This file also includes fields other than transaction fields.) The Transaction Format Reference also lists the internal formats for all transaction fields.
For example, the Flags common transaction field becomes a UInt32 (32-bit unsigned integer).
Definitions File
The following JSON file defines the important constants you need for serializing XRP Ledger data to its binary format and deserializing it from binary:
https://github.com/XRPLF/xrpl.js/blob/main/packages/ripple-binary-codec/src/enums/definitions.json
The following table defines the top-level fields from the definitions file:
| Field | Contents |
|---|---|
TYPES |
Map of data types to their "type code" for constructing field IDs and sorting fields in canonical order. Codes below 1 should not appear in actual data; codes above 10000 represent special "high-level" object types such as "Transaction" that cannot be serialized inside other objects. See the Type List for details of how to serialize each type. |
LEDGER_ENTRY_TYPES |
Map of ledger objects to their data type. These appear in ledger state data, and in the "affected nodes" section of processed transactions' metadata. |
FIELDS |
A sorted array of tuples representing all fields that may appear in transactions, ledger objects, or other data. The first member of each tuple is the string name of the field and the second member is an object with that field's properties. (See the "Field properties" table below for definitions of those fields.) |
TRANSACTION_RESULTS |
Map of transaction result codes to their numeric values. Result types not included in ledgers have negative values; tesSUCCESS has numeric value 0; tec-class codes represent failures that are included in ledgers. |
TRANSACTION_TYPES |
Map of all transaction types to their numeric values. |
For purposes of serializing transactions for signing and submitting, the FIELDS, TYPES, and TRANSACTION_TYPES fields are necessary.
The field definition objects in the FIELDS array have the following fields:
| Field | Type | Contents |
|---|---|---|
nth |
Number | The field code of this field, for use in constructing its Field ID and ordering it with other fields of the same data type. |
isVLEncoded |
Boolean | If true, this field is length-prefixed. |
isSerialized |
Boolean | If true, this field should be encoded into serialized binary data. When this field is false, the field is typically reconstructed on demand rather than stored. |
isSigningField |
Boolean | If true this field should be serialized when preparing a transaction for signing. If false, this field should be omitted from the data to be signed. (It may not be part of transactions at all.) |
type |
String | The internal data type of this field. This maps to a key in the TYPES map, which gives the type code for this field. |
Field IDs
[Source - Encoding] [Source - Decoding]
When you combine a field's type code and field code, you get the field's unique identifier, which is prefixed before the field in the final serialized blob. The size of the Field ID is one to three bytes depending on the type code and field codes it combines. See the following table:
| Type Code < 16 | Type Code >= 16 | |
|---|---|---|
| Field Code < 16 | 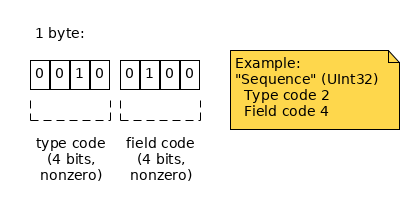 |
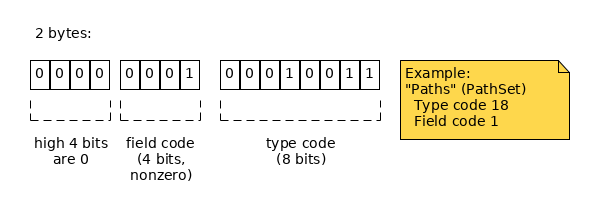 |
| Field Code >= 16 | 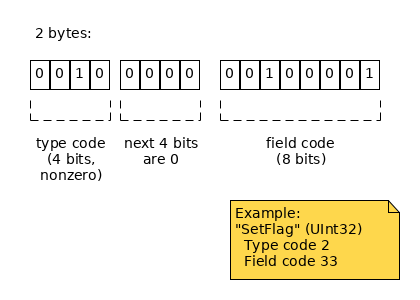 |
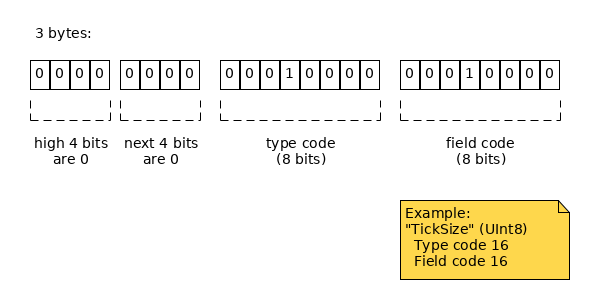 |
When decoding, you can tell how many bytes the field ID is by which bits of the first byte are zeroes. This corresponds to the cases in the above table:
| High 4 bits are nonzero | High 4 bits are zero | |
|---|---|---|
| Low 4 bits are nonzero | 1 byte: high 4 bits define type; low 4 bits define field. | 2 bytes: low 4 bits of the first byte define field; next byte defines type |
| Low 4 bits are zero | 2 bytes: high 4 bits of the first byte define type; low 4 bits of first byte are 0; next byte defines field | 3 bytes: first byte is 0x00, second byte defines type; third byte defines field |
Caution: Even though the Field ID consists of the two elements that are used to sort fields, you should not sort by the serialized Field ID itself, because the byte structure of the Field ID changes the sort order.
Length Prefixing
Some types of variable-length fields are prefixed with a length indicator. Blob fields (containing arbitrary binary data) are one such type. For a list of which types are length-prefixed, see the Type List table.
Note: Some types of fields that vary in length are not length-prefixed. Those types have other ways of indicating the end of their contents.
The length prefix consists of one to three bytes indicating the length of the field immediately after the type prefix and before the contents.
-
If the field contains 0 to 192 bytes of data, the first byte defines the length of the contents, then that many bytes of data follow immediately after the length byte.
-
If the field contains 193 to 12480 bytes of data, the first two bytes indicate the length of the field with the following formula:
193 + ((byte1 - 193) * 256) + byte2 -
If the field contains 12481 to 918744 bytes of data, the first three bytes indicate the length of the field with the following formula:
12481 + ((byte1 - 241) * 65536) + (byte2 * 256) + byte3 -
A length-prefixed field cannot contain more than 918744 bytes of data.
When decoding, you can tell from the value of the first length byte whether there are 0, 1, or 2 additional length bytes:
- If the first length byte has a value of 192 or less, then that's the only length byte and it contains the exact length of the field contents in bytes.
- If the first length byte has a value of 193 to 240, then there are two length bytes.
- If the first length byte has a value of 241 to 254, then there are three length bytes.
Canonical Field Order
All fields in a transaction are sorted in a specific order based first on the field's type (specifically, a numeric "type code" assigned to each type), then on the field itself (a "field code"). (Think of it as sorting by family name, then given name, where the family name is the field's type and the given name is the field itself.)
Type Codes
Each field type has an arbitrary type code, with lower codes sorting first. These codes are defined in SField.h .
For example, UInt32 has type code 2 , so all UInt32 fields come before all Amount fields, which have type code 6 .
The definitions file lists the type codes for each type in the TYPES map.
Field Codes
Each field has a field code, which is used to sort fields that have the same type as one another, with lower codes sorting first. These fields are defined in SField.cpp .
For example, the Account field of a Payment transaction has sort code 1 , so it comes before the Destination field which has sort code 3 .
Field codes are reused for fields of different field types, but fields of the same type never have the same field code. When you combine the type code with the field code, you get the field's unique Field ID.
Type List
Transaction instructions may contain fields of any of the following types:
| Type Name | Type Code | Bit Length | Length-prefixed? | Description |
|---|---|---|---|---|
| AccountID | 8 | 160 | Yes | The unique identifier for an account. |
| Amount | 6 | 64 or 384 | No | An amount of XRP or tokens. The length of the field is 64 bits for XRP or 384 bits (64+160+160) for tokens. |
| Blob | 7 | Variable | Yes | Arbitrary binary data. One important such field is TxnSignature, the signature that authorizes a transaction. |
| Hash128 | 4 | 128 | No | A 128-bit arbitrary binary value. The only such field is EmailHash, which is intended to store the MD-5 hash of an account owner's email for purposes of fetching a Gravatar . |
| Hash160 | 17 | 160 | No | A 160-bit arbitrary binary value. This may define a currency code or issuer. |
| Hash256 | 5 | 256 | No | A 256-bit arbitrary binary value. This usually represents the "SHA-512Half" hash of a transaction, ledger version, or ledger data object. |
| PathSet | 18 | Variable | No | A set of possible payment paths for a cross-currency payment. |
| STArray | 15 | Variable | No | An array containing a variable number of members, which can be different types depending on the field. Two cases of this include memos and lists of signers used in multi-signing. |
| STIssue | 24 | 160 or 320 | No | An asset definition, XRP or a token, with no quantity. |
| STObject | 14 | Variable | No | An object containing one or more nested fields. |
| UInt8 | 16 | 8 | No | An 8-bit unsigned integer. |
| UInt16 | 1 | 16 | No | A 16-bit unsigned integer. The TransactionType is a special case of this type, with specific strings mapping to integer values. |
| UInt32 | 2 | 32 | No | A 32-bit unsigned integer. The Flags and Sequence fields on all transactions are examples of this type. |
In addition to all of the above field types, the following types may appear in other contexts, such as ledger objects and transaction metadata:
| Type Name | Type Code | Length-prefixed? | Description |
|---|---|---|---|
| Transaction | 10001 | No | A "high-level" type containing an entire transaction. |
| LedgerEntry | 10002 | No | A "high-level" type containing an entire ledger object. |
| Validation | 10003 | No | A "high-level" type used in peer-to-peer communications to represent a validation vote in the consensus process. |
| Metadata | 10004 | No | A "high-level" type containing metadata for one transaction. |
| UInt64 | 3 | No | A 64-bit unsigned integer. This type does not appear in transaction instructions, but several ledger objects use fields of this type. |
| Vector256 | 19 | Yes | This type does not appear in transaction instructions, but the Amendments ledger object's Amendments field uses this to represent which amendments are currently enabled. |
AccountID Fields
Fields of this type contain the 160-bit identifier for an XRP Ledger account. In JSON, these fields are represented as base58 XRP Ledger "addresses", with additional checksum data so that typos are unlikely to result in valid addresses. (This encoding, sometimes called "Base58Check", prevents accidentally sending money to the wrong address.) The binary format for these fields does not contain any checksum data nor does it include the 0x00 "type prefix" used in address base58 encoding. (However, since the binary format is used mostly for signed transactions, a typo or other error in transcribing a signed transaction would invalidate the signature, preventing it from sending money.)
AccountIDs that appear as stand-alone fields (such as Account and Destination) are length-prefixed despite being a fixed 160 bits in length. As a result, the length indicator for these fields is always the byte 0x14. AccountIDs that appear as children of special fields (Amount issuer and PathSet account) are not length-prefixed.
Amount Fields
The "Amount" type is a special field type that represents an amount of currency, either XRP or a token. This type consists of two sub-types:
-
XRP
XRP is serialized as a 64-bit unsigned integer (big-endian order), except that the most significant bit is always 0 to indicate that it's XRP, and the second-most-significant bit is
1to indicate that it is positive. Since the maximum amount of XRP (1017 drops) only requires 57 bits, you can calculate XRP serialized format by taking standard 64-bit unsigned integer and performing a bitwise-OR with0x4000000000000000. -
Tokens
Tokens consist of three segments in order:
- 64 bits indicating the amount in the token amount format. The first bit is
1to indicate that this is not XRP. - 160 bits indicating the currency code. The standard API converts 3-character codes such as "USD" into 160-bit codes using the standard currency code format, but custom 160-bit codes are also possible.
- 160 bits indicating the issuer's Account ID. (See also: Account Address Encoding)
- 64 bits indicating the amount in the token amount format. The first bit is
You can tell which of the two sub-types it is based on the first bit: 0 for XRP; 1 for tokens.
The following diagram shows the serialization formats for both XRP amounts and token amounts:
{kind=link}
Token Amount Format
{kind=link}
The XRP Ledger uses 64 bits to serialize the numeric amount of a (fungible) token. (In JSON format, the numeric amount is the value field of a currency amount object.) In binary format, the numeric amount consists of a "not XRP" bit, a sign bit, significant digits, and an exponent, in order:
- The first (most significant) bit for a token amount is
1to indicate that it is not an XRP amount. (XRP amounts always have the most significant bit set to0to distinguish them from this format.) - The sign bit indicates whether the amount is positive or negative. Unlike standard two's complement integers,
1indicates positive in the XRP Ledger format, and0indicates negative. - The next 8 bits represent the exponent as an unsigned integer. The exponent indicates the scale (what power of 10 the significant digits should be multiplied by) in the range -96 to +80 (inclusive). However, when serializing, we add 97 to the exponent to make it possible to serialize as an unsigned integer. Thus, a serialized value of
1indicates an exponent of-96, a serialized value of177indicates an exponent of 80, and so on. - The remaining 54 bits represent the significant digits (sometimes called a mantissa) as an unsigned integer. When serializing, this value is normalized to the range 1015 (
1000000000000000) to 1016-1 (9999999999999999) inclusive, except for the special case of the value 0. In the special case for 0, the sign bit, exponent, and significant digits are all zeroes, so the 64-bit value is serialized as0x8000000000000000000000000000000000000000.
The numeric amount is serialized alongside the currency code and issuer to form a full token amount.
Currency Codes
At a protocol level, currency codes in the XRP Ledger are arbitrary 160-bit values, except the following values have special meaning:
- The currency code
0x0000000000000000000000005852500000000000is always disallowed. (This is the code "XRP" in the "standard format".) - The currency code
0x0000000000000000000000000000000000000000(all zeroes) is generally disallowed. Usually, XRP amounts are not specified with currency codes. However, this code is used to indicate XRP in rare cases where a field must specify a currency code for XRP.
The rippled APIs support a standard format for translating three-character ASCII codes to 160-bit hex values as follows:
{kind=link}
- The first 8 bits must be
0x00. - The next 88 bits are reserved, and should be all
0's. - The next 24 bits represent 3 characters of ASCII.
Ripple recommends using ISO 4217 codes, or popular pseudo-ISO 4217 codes such as "BTC". However, any combination of the following characters is permitted: all uppercase and lowercase letters, digits, as well as the symbols
?,!,@,#,$,%,^,&,*,<,>,(,),{,},[,], and|. The currency codeXRP(all-uppercase) is reserved for XRP and cannot be used by tokens. - The next 40 bits are reserved and should be all
0's.
The nonstandard format is any 160 bits of data as long as the first 8 bits are not 0x00.
Array Fields
Some transaction fields, such as SignerEntries (in SignerListSet transactions) and Memos, are arrays of objects (called the "STArray" type).
Arrays contain several object fields in their native binary format in a specific order. In JSON, each array member is a JSON "wrapper" object with a single field, which is the name of the member object field. The value of that field is the ("inner") object itself.
In the binary format, each member of the array has a Field ID prefix (based on the single key of the wrapper object) and contents (comprising the inner object, serialized as an object). To mark the end of an array, append an item with a "Field ID" of 0xf1 (the type code for array with field code of 1) and no contents.
The following example shows the serialization format for an array (the SignerEntries field):
{kind=link}
Blob Fields
The Blob type is a length-prefixed field with arbitrary data. Two common fields that use this type are SigningPubKey and TxnSignature, which contain (respectively) the public key and signature that authorize a transaction to be executed.
Blob fields have no further structure to their contents, so they consist of exactly the amount of bytes indicated in the variable-length encoding, after the Field ID and length prefixes.
Hash Fields
The XRP Ledger has several "hash" types: Hash128, Hash160, and Hash256. These fields contain arbitrary binary data of the given number of bits, which may or may not represent the result of a hash operation.
All such fields are serialized as the specific number of bits, with no length indicator, in big-endian byte order.
Issue Fields
(The "Issue" or "STIssue" type is part of multiple proposed extensions to the XRP Ledger protocol, including XLS-30d: Automated Market Maker and Federated Sidechains )
Some fields specify a type of asset, which could be XRP or a fungible token, without an amount. These fields have consist of one or two 160-bit segments in order:
- The first 160 bits are the currency code of the asset. For XRP, this is all 0's.
- If the first 160 bits are all 0's (the asset is XRP), the field ends there. Otherwise, the asset is a token and the next 160 bits are the AccountID of the token issuer.
Object Fields
Some fields, such as SignerEntry (in SignerListSet transactions), and Memo (in Memos arrays) are objects (called the "STObject" type). The serialization of objects is very similar to that of arrays, with one difference: object members must be placed in canonical order within the object field, where array fields have an explicit order already.
The canonical field order of object fields is the same as the canonical field order for all top-level fields, but the members of the object must be sorted within the object. After the last member, there is an "Object end" Field ID of 0xe1 with no contents.
The following example shows the serialization format for an object (a single Memo object in the Memos array).
{kind=link}
PathSet Fields
The Paths field of a cross-currency Payment transaction is a "PathSet", represented in JSON as an array of arrays. For more information on what paths are used for, see Paths.
A PathSet is serialized as 1 to 6 individual paths in sequence[Source] . Each complete path is followed by a byte that indicates what comes next:
0xffindicates another path follows0x00indicates the end of the PathSet
Each path consists of 1 to 8 path steps in order[Source] . Each step starts with a type byte, followed by one or more fields describing the path step. The type indicates which fields are present in that path step through bitwise flags. (For example, the value 0x30 indicates changing both currency and issuer.) If more than one field is present, the fields are always placed in a specific order.
The following table describes the possible fields and the bitwise flags to set in the type byte to indicate them:
| Type Flag | Field Present | Field Type | Bit Size | Order |
|---|---|---|---|---|
0x01 |
account |
AccountID | 160 bits | 1st |
0x10 |
currency |
Currency Code | 160 bits | 2nd |
0x20 |
issuer |
AccountID | 160 bits | 3rd |
Some combinations are invalid; see Path Specifications for details.
The AccountIDs in the account and issuer fields are presented without a length prefix. When the currency is XRP, the currency code is represented as 160 bits of zeroes.
Each step is followed directly by the next step of the path. As described above, the last step of a path is followed by either 0xff (if another path follows) or 0x00 (if this ends the last path).
The following example shows the serialization format for a PathSet:
{kind=link}
UInt Fields
The XRP Ledger has several unsigned integer types: UInt8, UInt16, UInt32, and UInt64. All of these are standard big-endian binary unsigned integers with the specified number of bits.
When representing these fields in JSON objects, most are represented as JSON numbers by default. One exception is UInt64, which is represented as a string because some JSON decoders may try to represent these integers as 64-bit "double precision" floating point numbers, which cannot represent all distinct UInt64 values with full precision.
Another special case is the TransactionType field. In JSON, this field is conventionally represented as a string with the name of the transaction type, but in binary, this field is a UInt16. The TRANSACTION_TYPES object in the definitions file maps these strings to specific numeric values.